はじめに
プリントシール機のソフトウェア開発をしております米田です。
本記事では、プリントシール機(以下「プリ機」と称する)におけるプレイデータの取得の方法と、その新しい展開について記します。
そもそもプレイデータとは
どんな機能がユーザーに望まれているか、プリ機でユーザーがどう遊んでいるのか……
ユーザーの動向を知ることは、商品開発において非常に重要です。
その答えを得る手段は多岐にわたり、一例としては以下のようなものがあります。
- ゲームセンターでプレイしたユーザーにアンケートを取る
- ユーザーをフリューに招いてインタビューを実施する
- プリ機に記録された操作データを取得する
今回はその中でも、プリ機に記録された操作データについてのお話となります。
どんなデータを取得しているか
プリ機に記録された操作データとは、各画面の遷移時間であったり、どの機能を使用しているかといった操作情報のことで、大きく以下の2種類の区分でデータを取得しています。
- 1プレイにフォーカスしてそのユーザーの動向を取得するユーザー特化データ
- そのプリ機で1日にプレイされた各種操作データを集計した筐体プレイデータ
この2つを見た時に、一つ疑問が浮かんでくると思います。
前者のユーザー特化データですべて取得してしまえば、後者のデータも自ずと取得できるのでは?と
もっともな意見だと思います。
データが2種類ある理由は、プリ機の通信環境とレガシーシステムの使用であると考えています。
プリ機の通信は設置店舗の立地条件にも依りますが、
プリ機自体に搭載されている通信端末を利用して行っており、通信量には厳しい制限(送信サイズとしては、ユーザーに提供する携帯画像や機種固有のコンテンツすべてを合算して7MB程度)があります。
また、このシステムは古くは20年近く前のプリ機から搭載しています。
今でこそ、Gbps級の高速通信は当たり前というご時世ですが、その通信量が当時どれぐらい貴重だったかは想像に難くないところです(現在のデータ送信サイズは上記の通り7MB程度ですが、初期の機種ではわずか80KB程度であったと言われています)。
以上から、ユーザー特化データは最小限のデータ内容を毎プレイ取得し送信、
筐体プレイデータはユーザー特化データより詳細な項目はあるものの、そのデータの送信は1日1回だけとなっています。
実際に取得しているプレイデータ例
ここで、どんなデータを取得しているかも軽く紹介していきましょう。
ユーザー特化データでは特に、そのプリ機固有の新機能に注目して、 ヘビーユーザー/ライトユーザーの動向や、新機能同士の親和性等も取得できるように 最小限と言いつつ吟味しながら取得する内容を検討します。
一方で筐体プレイデータでは、各画面のユーザー選択結果や操作履歴を一通り取得しています。少し変わったところですと、撮影時の顔認識の情報から撮影時の人数も取得していたりします。撮影時の顔が対象となっていますが、肖像権に関わるデータは原則的に操作できないようになっており、ここで取得しているのはあくまで顔の数という情報となります。
以下は、取得した筐体プレイデータを集計して閲覧サイトで見た際の例となります。

これらの情報を元に、リリースしたプリ機の評価や、新機種/次バージョン開発のターゲットや機能の検討に役立てていきます。
クラウド活用によるデータ管理の模索
ここまでは現状のデータ取得の概要やその中身についてお話してきましたが、
現在検討中の既存システムを元にした別システムについても、お話しできればと思います。
前述の通り、1プレイで送信できるデータサイズに厳しい制限があることに現状変わりはありませんが、それ以上に、ユーザーの利用情報の活用や管理が重要な課題となります。
また、現在のシステムが古くから動いているシステムのため、メンテナンスも難しくなってきています。
つまりはシステムの代替わりの必要性が出てきたということです。
そこで白羽の矢が立ったのがアマゾン ウェブ サービスやGoogle Cloudといったクラウドサービスです。
今や、多くのシーンで導入されているクラウドサービスですが、フリューにおいても各所で導入されています。
といっても、今まで得てきたプリ機の情報を切り捨てて一足飛びに新しいシステムにしようという話ではなく、現在送っているデータを有効活用する方法を目指します。
以下が、変更前後の模式図となります。
今回は、Google Cloudのサービスを利用する形で検討を進めました。
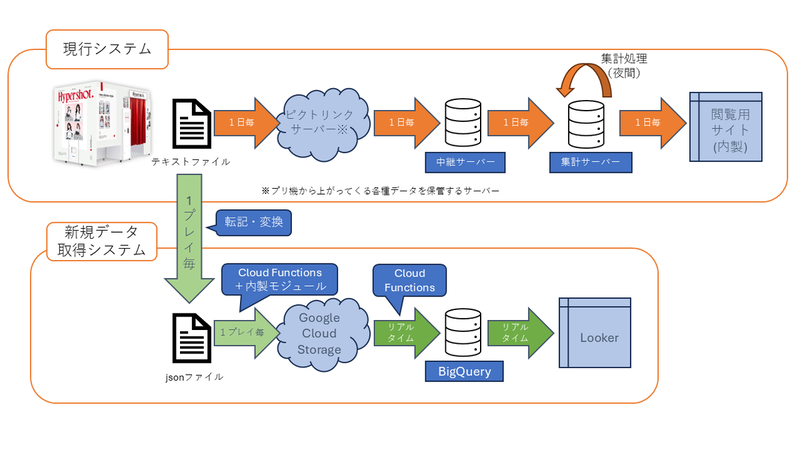
既存の送信ファイル作成の処理に今回の処理を追加するのではなく、
既存の中間ファイルを読み込み、転記してからアップロードすることとしました。
なお、セキュリティ面を考慮し、一度Cloud Functionsに署名付きURLの発行処理を依頼し
受け取ったURLへファイルのアップロードを行う形を取っています。
このCloud Functions周りのGoogle Cloudとのやりとりは以下の図の通り
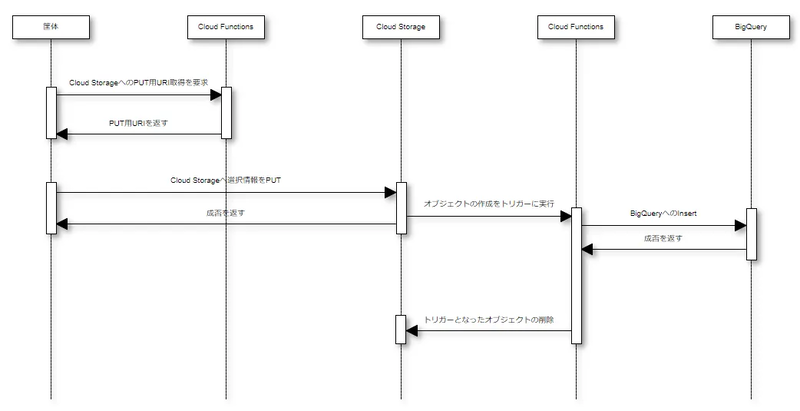
このように、Google Cloud StorageへアップロードされたファイルはBigQueryに登録され、既存の送信内容と同等のデータの取得が可能となります。
また、図内の矢印を比較してもらえるとわかるのですが、
データの即時性が著しく向上しているのが分かると思います。
おわりに
検証として搭載した本システムですが、
プリ機の通信環境の安定性の課題もあり、システムの入れ替えにはまだ至っていません。
ただ、この取り組みを進めることで、現在2種類送信しているデータの統合が実現され、ユーザー特化データの内容も拡充されます。
より良い商品開発を実現のためにも、引き続き推し進めていく所存です。